Merkle Tries and Verifiable Blockchain State

Blockchains are often introduced as ledgers, but the more interesting engineering problem is state.
Modern chains maintain a large key-value database that changes every block: account balances, staking ledgers, governance tracks, scheduler queues, proxy definitions, identity records, parachain heads, smart contract storage, and anything else the runtime decides to persist.
That database needs a property that ordinary application databases do not usually need: anyone should be able to verify a small part of it without trusting the machine that served the data. This is where Merkle tries come in.
In this article I will walk through what Merkle tries are, how a typical database layout can support them, how querying works in a blockchain context, and how the Polkadot SDK implements the idea through its state trie stack.
The problem Merkle tries solve
An ordinary key-value store gives us fast reads:
key -> value
For example:
System.Account(Alice) -> AccountInfo { nonce, consumers, providers, data }
Balances.TotalIssuance -> <encoded total issuance>
Staking.Ledger(Alice) -> StakingLedger { stash, total, active, ... }
This is fine if we trust the database. But in a blockchain, the database is usually accessed through a remote node. A wallet, dashboard, indexer, light client, bridge, or parachain validator may need to ask another machine:
What was the value of this storage key at block X?
The node can send back a value, but the client also needs a way to know that the value belongs to the canonical state committed by that block.
The compact commitment to the whole state is the state root. Each block header includes this root, and consensus finalizes the block header. If a client trusts the finalized header, it can verify storage proofs against the state root without downloading the full state database. The Merkle trie is the data structure that makes that possible.

Merkle trie state root flow.
What is a Merkle trie?
A Merkle trie combines three ideas:
- A trie, which indexes keys by their prefixes.
- Patricia-style compression, which avoids storing a separate node for every single character or nibble when paths do not branch.
- Merkle hashing, where each node commits to its children and value, so the root hash commits to the whole database.
The trie part gives us an ordered key path. The Merkle part gives us verifiability. The Patricia-style compression keeps the structure smaller than a naive prefix tree.
Polkadot SDK's trie is a base-16 modified Merkle Patricia trie. Base-16 means each byte of a storage key is interpreted as two 4-bit nibbles, and each branch can have up to 16 children.
byte key: 0x3f7a
nibble path: 3 -> f -> 7 -> a
This matters because a storage key is not treated as a string. It is a byte sequence. The trie walks through those bytes nibble by nibble until it finds the node that stores the value or proves the value is absent.
Conceptually, a trie node contains:
- A partial key path.
- Up to 16 child references.
- Optionally, a value.
- Enough encoded data for a hash to be calculated deterministically.
The child reference is either the encoded child node itself, if small enough to inline, or the hash of the encoded child node. That detail matters for database design: many trie databases are content-addressed, where the hash of a node is also the lookup key for the node's encoded bytes.
A small example
Assume we have these storage keys:
0x1234aa -> Alice balance
0x1234bb -> Bob balance
0x129999 -> Total issuance
They share a prefix, so the trie does not store three completely separate paths.
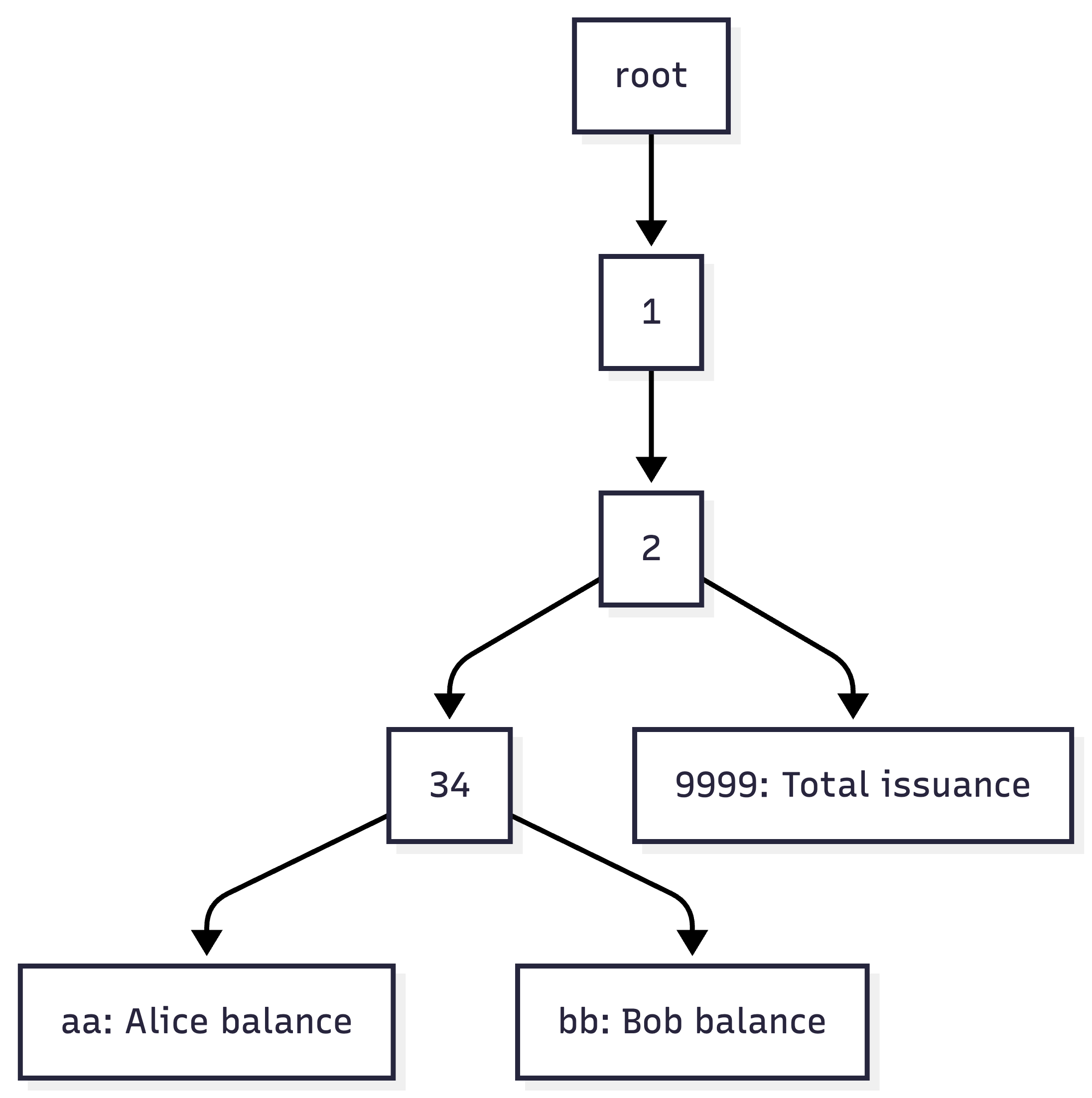
Merkle trie prefix breakdown.
In a real implementation, this is encoded much more compactly than the diagram suggests. The important point is that shared prefixes are represented once, and a change to 0x1234aa only changes the nodes along that path back to the root.
That gives Merkle tries their useful update property:
Update one key
-> change leaf or branch on that key path
-> recalculate ancestor hashes
-> produce a new root
We do not need to hash every key-value pair in the database after every block.
How updates work
At a high level, inserting or updating a value follows this flow:
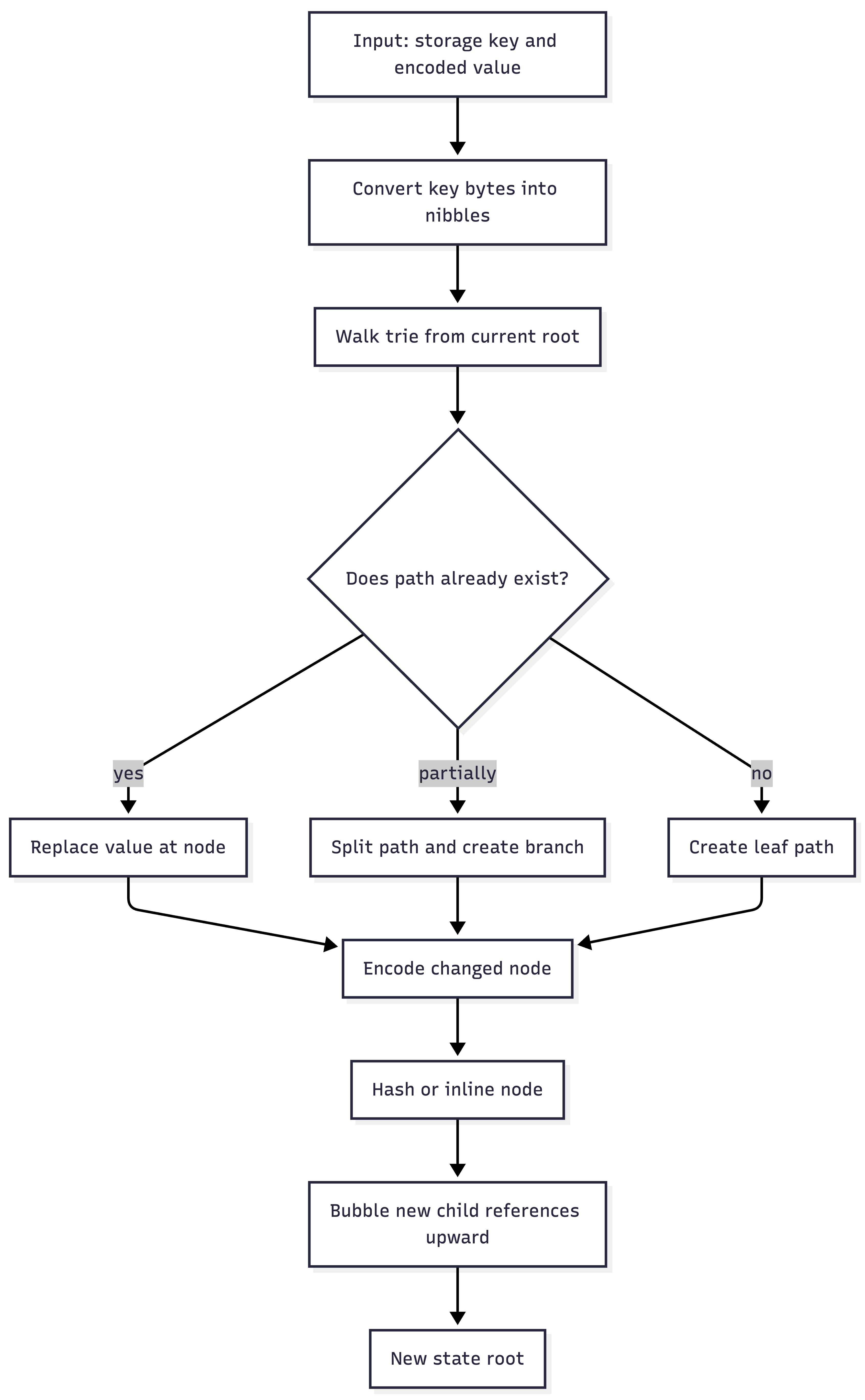
Merkle trie value update flow.
The new root is deterministic. Every honest node that starts from the same previous state, applies the same extrinsics, and uses the same trie layout will calculate the same root.
This is why block verification can be reduced to a very practical check:
- Start from the parent state.
- Execute the block's extrinsics.
- Apply the storage changes.
- Recalculate the state root.
- Check that it matches the
state_rootin the block header.
If it does not match, the block is invalid.
The database behind a Merkle trie
It is tempting to think of a Merkle trie as the database itself. In practice, it is better to think of it as the authenticated index on top of a database.
The backing store is usually a key-value database such as RocksDB or ParityDB. The trie layer controls how state is encoded, hashed, updated, and proven.
A typical low-level storage model looks like this:
node_hash -> encoded_trie_node
The encoded node contains child references and maybe a value. If a child is too large to inline, the encoded node stores the child's hash. The database can then retrieve the child node by that hash.
For a blockchain node, we also need block metadata, state root metadata, reference tracking, and sometimes a flat key-value cache to make execution faster.
Logical tables
If we model the system with SQL-like tables, the shape would look something like this.
CREATE TABLE block_headers (
block_hash BINARY(32) PRIMARY KEY,
parent_hash BINARY(32) NOT NULL,
block_number BIGINT NOT NULL,
state_root BINARY(32) NOT NULL,
extrinsics_root BINARY(32) NOT NULL,
digest BLOB NOT NULL
);
CREATE TABLE state_roots (
state_root BINARY(32) PRIMARY KEY,
block_hash BINARY(32) NOT NULL,
state_version SMALLINT NOT NULL,
created_at BIGINT NOT NULL
);
CREATE TABLE trie_nodes (
node_hash BINARY(32) PRIMARY KEY,
encoded_node BLOB NOT NULL,
ref_count BIGINT NOT NULL DEFAULT 0,
first_seen_block BIGINT,
last_seen_block BIGINT
);
CREATE TABLE state_changes (
block_hash BINARY(32) NOT NULL,
storage_key BLOB NOT NULL,
old_value_hash BINARY(32),
new_value_hash BINARY(32),
operation TEXT NOT NULL,
PRIMARY KEY (block_hash, storage_key)
);
CREATE TABLE flat_storage_cache (
storage_key BLOB PRIMARY KEY,
storage_value BLOB,
value_hash BINARY(32),
updated_at_block BIGINT NOT NULL
);
This is not meant to imply that Polkadot SDK literally stores state in these SQL tables. It does not. The SDK abstracts over hash databases, state backends, and client databases. The table view is useful because it separates the concerns:
block_headerscommits to state roots.state_rootsrecords which trie root belongs to which block and state version.trie_nodesstores content-addressed trie nodes.state_changeshelps pruning, rollback, auditing, and historical reconstruction.flat_storage_cacheis an execution optimization, not the cryptographic source of truth.
The essential table is trie_nodes. Everything else exists because blockchains need history, forks, pruning, and fast state execution.
Key-value column families
In a production key-value database, the same idea is more likely to be represented as column families:
| Column family | Key | Value | Purpose |
|---|---|---|---|
headers | block_hash | encoded header | Retrieve block number, parent, state root, extrinsics root |
state_meta | state_root | state version, block hash, pruning metadata | Know how to interpret a root |
trie_nodes | node_hash | encoded trie node | Traverse and prove trie paths |
state_changes | block_hash | changed keys and node refs | Revert, prune, or audit changes |
flat_state | storage_key | current value | Optional cache for fast runtime reads |
proof_cache | proof key | encoded proof nodes | Optional short-lived cache for repeated proof requests |
The trie itself only needs node_hash -> encoded_node. Blockchain nodes usually need the rest.
How querying works
There are two different query modes to keep separate:
- A trusted full node query, where the node reads its local database and returns a decoded value.
- A verifiable query, where the node returns proof data that contains the relevant trie nodes and storage value, or returns the value alongside proof data depending on the API.
For a dApp using a typed API, the query feels simple:
const account = await client.query.system.account(address)
Underneath that call, several things happen:
- Runtime metadata tells the client how to construct the storage key.
- The storage key is SCALE-encoded and hashed according to the storage item definition.
- The node reads the value at that key, usually at the latest finalized or best block.
- The raw SCALE-encoded storage value is decoded back into a typed object.
For a lower-level query, the key construction is explicit:
storage_key =
twox128(pallet_prefix)
++ twox128(storage_prefix)
++ storage_hasher(scale_encode(map_key))
For a StorageValue, there is no map key. For a StorageMap, the storage prefix is extended with the hashed encoded key. For a StorageDoubleMap or NMap, more key segments are appended.
In Polkadot SDK FRAME storage, this prefix begins with:
twox128(pallet_prefix) ++ twox128(STORAGE_PREFIX)
The map's configured hasher is then applied to each encoded map key. Common hashers include Blake2_128Concat, Twox64Concat, Twox128, Blake2_256, and Identity.
Once the node has the raw storage key, trie lookup is deterministic:
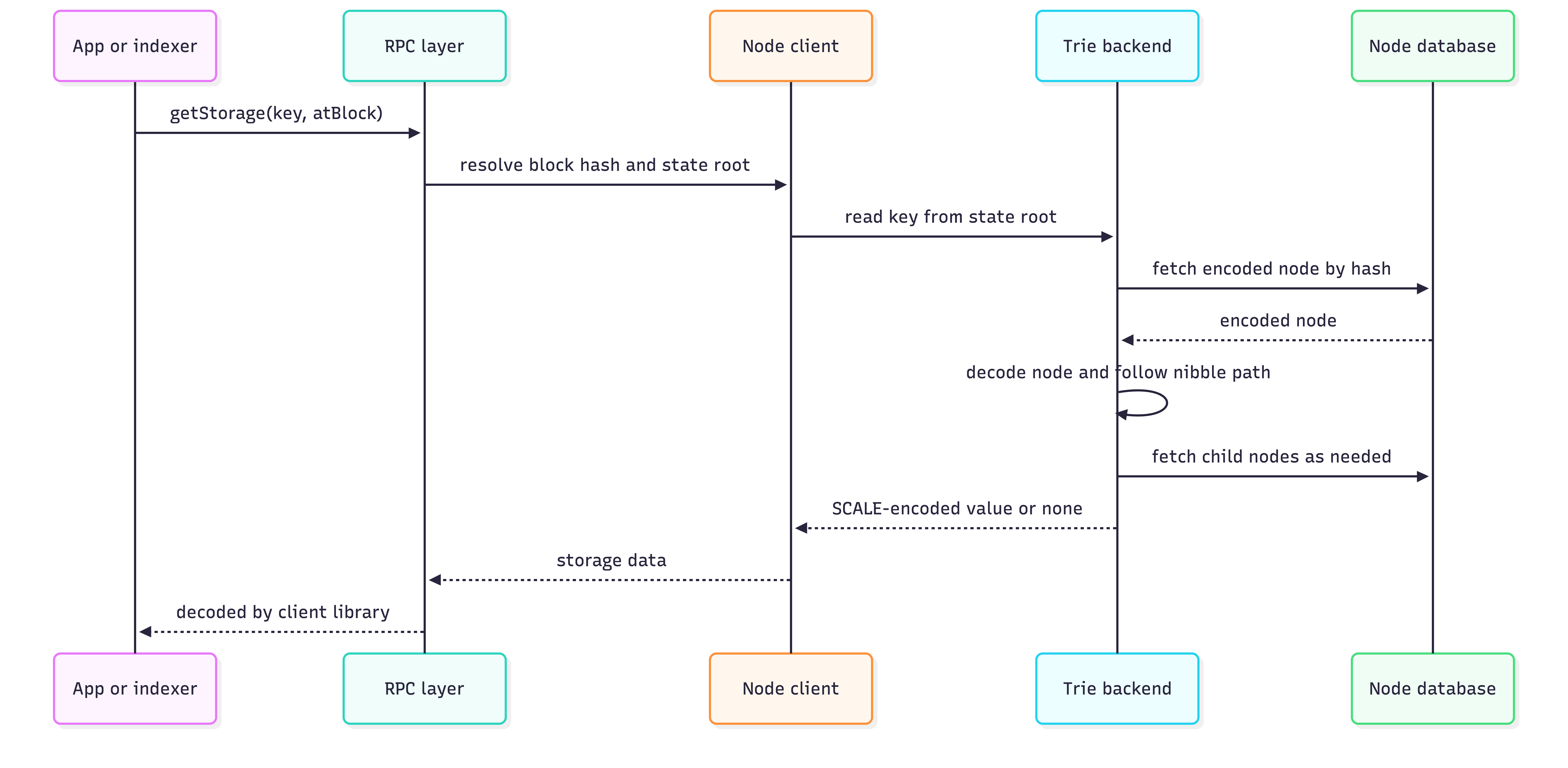
Trie lookup flow.
The proof flow is similar, but the node records every trie node required to justify the answer.
Proof flow.
A proof is not a second database. It is a small collection of encoded nodes that lets the verifier reconstruct just enough of the trie to check the root.
Why this matters in blockchain clients
The immediate benefit is trust minimization.
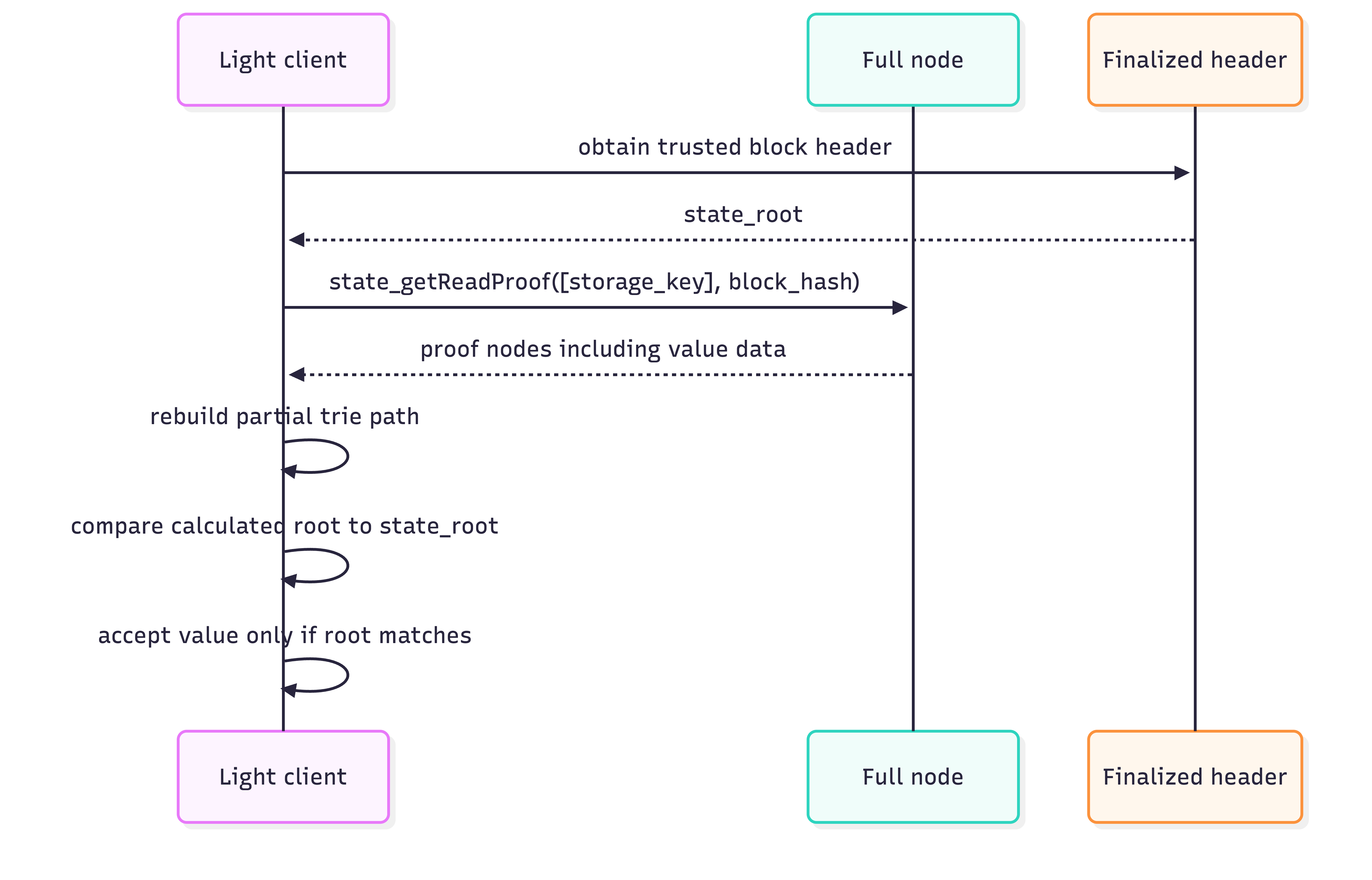
A browser app can ask a public RPC node for a balance. If it only gets the balance, it trusts the RPC node. If it gets a storage proof and already has a trusted finalized header, it can verify the balance against the state root in that header.
This is also why Merkle tries are central to light clients. A light client does not store the full state, but it can still verify:
- A specific account's storage value.
- The absence of a value.
- A range of storage keys, if the proof format supports range proofs.
- Runtime execution witnesses, where validators or verifiers need the state touched by an execution.
The state root becomes the compact cryptographic boundary between consensus and storage.
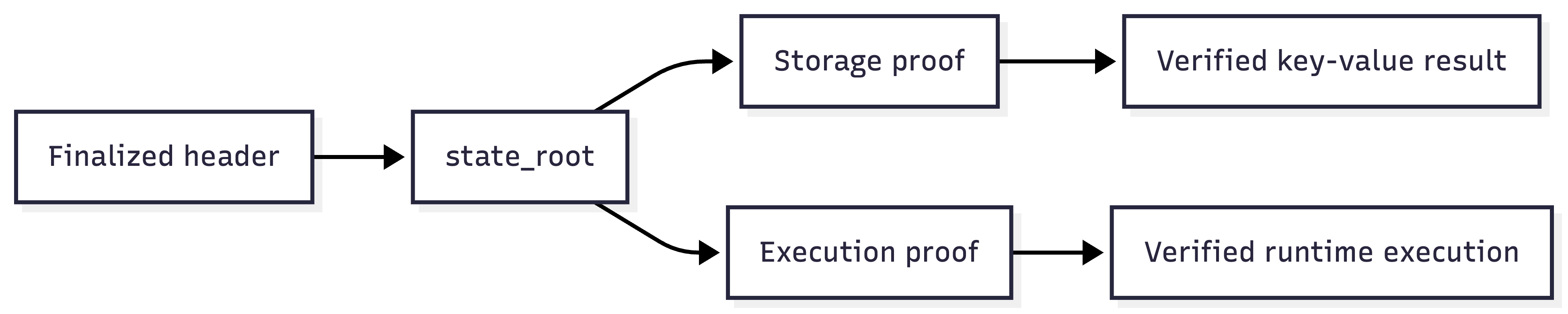
Finalized header.
Polkadot SDK's implementation
Polkadot SDK uses Substrate as the base framework. Substrate-based chains maintain a main state trie, and the root of that trie is committed in the block header.
The relevant crates and layers are:
| Layer | Polkadot SDK component | Role |
|---|---|---|
| Trie primitives | sp_trie | Base-16 modified Merkle Patricia trie utilities, layouts, proofs, node codec |
| Generic trie implementation | trie-db | Persistent trie read/write interfaces over a hash database |
| State execution | sp_state_machine | Trie-backed state backend, overlays, proof generation and checking |
| Client API | sc_client_api | Client-facing proof and storage APIs |
| Runtime storage | FRAME storage macros | Storage key layout and typed pallet storage |
| Node database | RocksDB or ParityDB integrations | Persist headers, trie nodes, metadata, and state data |
The sp_trie crate exposes the core trie machinery. Its documentation describes it as utility functions for Substrate's base-16 modified Merkle Patricia trie. It includes:
LayoutV0andLayoutV1.NodeCodec, the Substrate trie node codec using SCALE encoding.TrieDBandTrieDBMutre-exports fromtrie-db.StorageProof.- Helpers such as
read_trie_value,generate_trie_proof, andverify_trie_proof.
LayoutV1 is especially important because it supports external value nodes. In practice, this helps keep proofs smaller and more predictable when values are large. The Polkadot ecosystem introduced state trie versioning so chains could migrate trie behavior without pretending the encoding never changed.
The state machine layer then uses this trie backend when executing runtime logic:
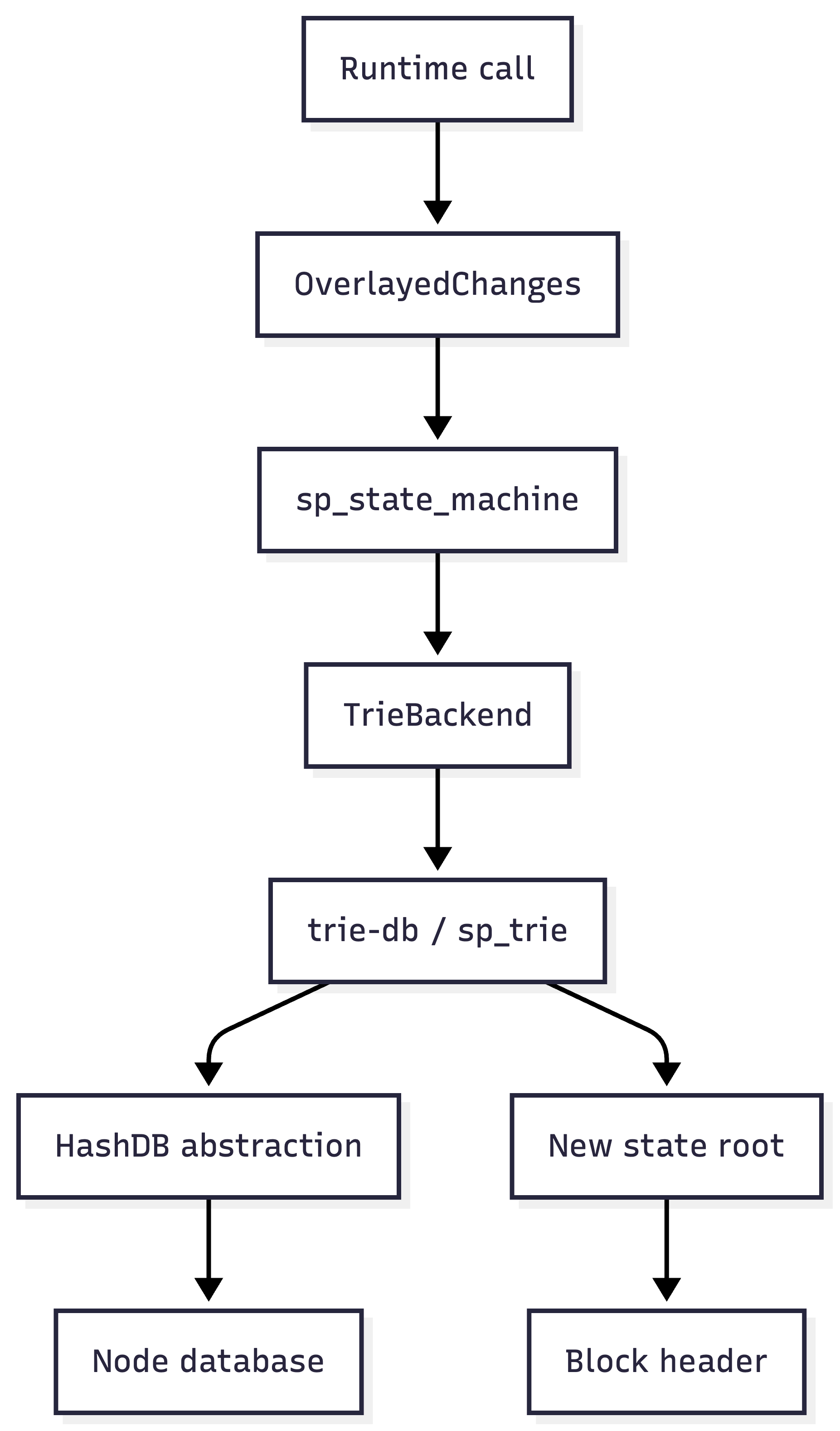
Runtime logic execution.
The overlay is important. During execution, storage writes are collected as changes over the existing backend. When the block is finalized locally, those changes are committed into the trie backend, producing a new state root and the database updates needed to persist the new nodes.
Storage keys in FRAME
FRAME storage is strongly typed at the runtime level, but the trie only sees bytes.
Take a storage map such as:
#[pallet::storage]
pub type Account<T: Config> =
StorageMap<_, Blake2_128Concat, T::AccountId, AccountInfo<T::Nonce, T::AccountData>>;
The raw storage key is built from:
twox128("System") ++ twox128("Account") ++ blake2_128_concat(scale_encode(account_id))
The trie does not know that this is System.Account. It just sees a byte key. Metadata and client libraries give that byte key meaning.
This is why typed clients are so valuable. A library can hide the storage key construction and decode path:
const accountInfo = await client.query.system.account(accountId)
But under the hood, this is still a trie lookup against a raw storage key at a particular state root.
Querying Polkadot-style state
At the JSON-RPC level, common state methods include:
| RPC method | Purpose |
|---|---|
state_getStorage | Read a storage value for a key at an optional block hash |
state_getStorageHash | Read the hash of a storage value |
state_getStorageSize | Read encoded storage size |
state_getKeysPaged | Page through keys with a prefix |
state_queryStorageAt | Query storage entries at a block |
state_getReadProof | Return a proof for storage entries at a block state |
state_getChildReadProof | Return a proof for child trie storage entries |
For app development, I would still avoid hand-writing these calls unless there is a clear reason. A typed client such as Dedot, Subxt, or Polkadot JS API can use runtime metadata to construct the key and decode the value.
The low-level RPCs become valuable when building:
- Light client verification.
- Bridges.
- Indexers that need precise block-specific state.
- Debug tooling.
- Proof-aware API services.
- Runtime migration tooling.
Child tries
Polkadot SDK also supports child tries. A child trie is a separate trie whose root is referenced from the top-level state. This is useful when a module needs isolated storage with its own root, while still anchoring that root in the main state trie.
The important mental model:
top-level state trie
storage key -> child trie root
child trie
child key -> child value
Proofs involving child tries need to prove both:
- The child trie root is present in the top-level state trie.
- The child value is present in the child trie under that root.
The sp_state_machine docs mention that the state machine allows a single level of child trie nesting. This keeps proof and execution semantics bounded.
Read proof anatomy
A storage proof for one key needs the nodes on the path from the root to the target value, plus enough sibling information at each branch to recalculate the same hashes.
For a radix-16 trie, each branch may reference up to 16 child positions. The proof does not include the whole database, but it includes enough encoded branch data to make the path verifiable.
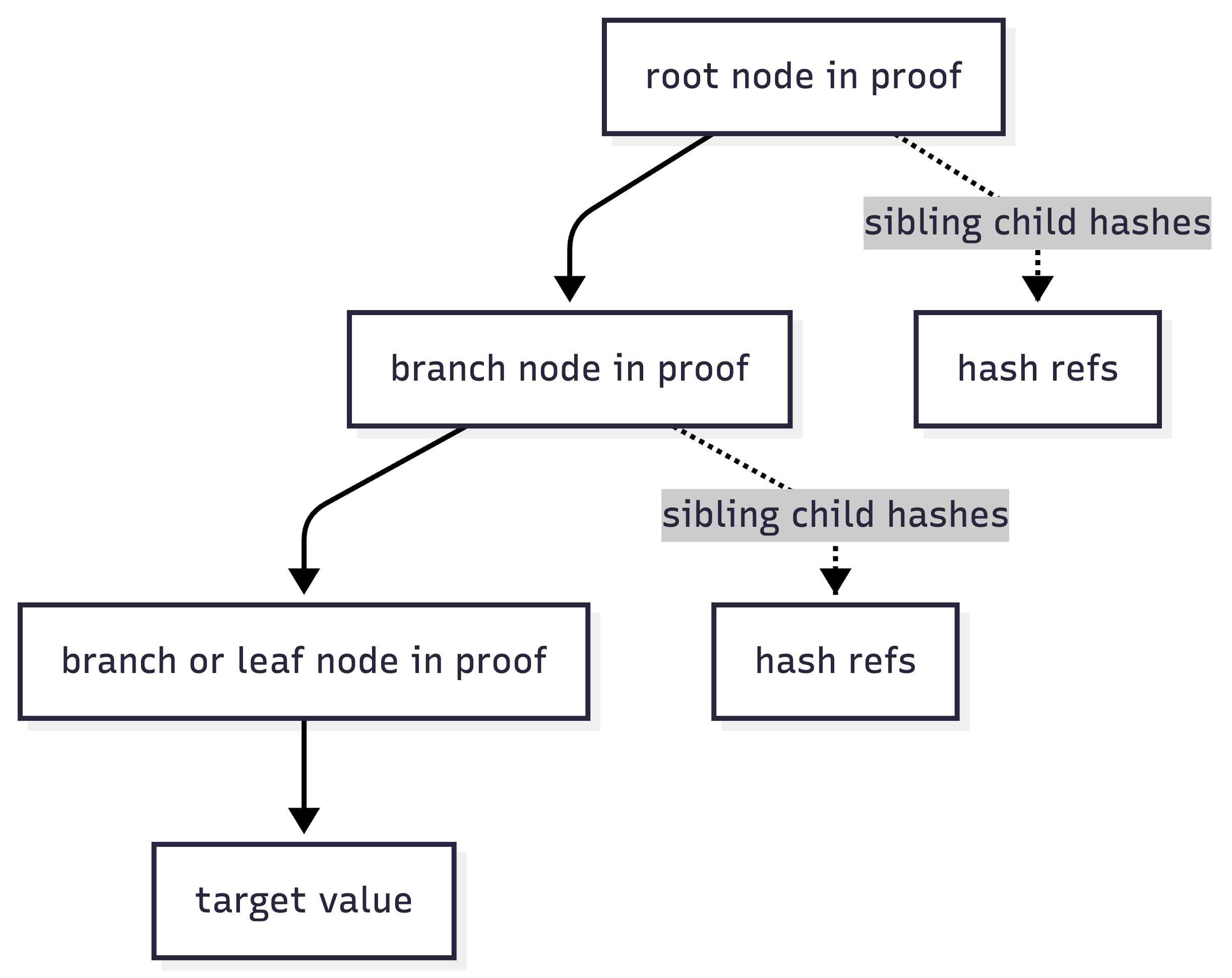
Child trie path.
The verifier checks:
- Decode the proof nodes.
- Walk the requested key path.
- Confirm the value or absence claim.
- Re-hash nodes back to the root.
- Compare the calculated root to the trusted
state_root.
If a single byte in the value or path is changed, the calculated root changes.
What gets stored in the trie?
The state trie stores runtime storage. It does not directly store every piece of block data.
The header, extrinsics, and consensus digest live in block storage. The state trie stores the key-value state that results from executing the runtime. Some runtime items are block-scoped, such as events, because the runtime stores them. Other block data, such as the extrinsics themselves, are committed separately through the extrinsics root.
This distinction is important:
| Data | In state trie? | Notes |
|---|---|---|
| Account info | Yes | Runtime storage under System.Account |
| Balances total issuance | Yes | Runtime storage item |
| Staking ledger | Yes | Runtime storage item |
| Events | Usually yes for the block | Runtime stores events in state |
| Extrinsics | No | Committed by extrinsics root |
| Block header | No | Stored in block database |
| Consensus digest | No | Part of header |
The state trie is the runtime's database, not the whole node database.
Practical implementation notes
There are a few details that make Merkle trie implementations more subtle than they first appear.
1. The raw storage key is already structured
FRAME storage keys include pallet and storage prefixes. Map keys are SCALE-encoded and hashed with the storage hasher configured by the runtime. This lets keys sharing the same pallet and storage item sit under the same prefix, which enables prefix iteration.
2. The trie root is a commitment, not a query index
The state root is useful because it commits to everything. It is not enough by itself to answer a query. A node still needs the trie nodes behind the root, or a proof containing those nodes.
3. Small nodes can be inlined
Polkadot SDK's trie abstractions distinguish between Merkle values that are node data and Merkle values that are hashes. This reduces database lookups for small nodes, but it also means implementers need to be precise about encoding thresholds and state versions.
4. State version matters
Polkadot SDK has state trie versions. LayoutV0 and LayoutV1 encode values differently, and runtime versions expose the state version used for updates. A proof verifier must use the correct layout.
5. Historical queries depend on pruning mode
Archive nodes can serve historical state far back in time. Pruned nodes may only retain recent state. The block header still commits to old state, but a node cannot serve a proof if it no longer has the required trie nodes.
6. A flat cache is not a substitute for the trie
A node may keep flat key-value state for fast execution. That is an optimization. The trie is still needed to produce the state root and proofs.
A complete read path
Putting it all together, a verifiable read from a Polkadot SDK-based chain looks like this:
Polkadot SDK read path.
For normal UI development, most of this is handled below the app layer. For infrastructure, it is worth understanding the whole flow because it explains why node APIs, metadata, SCALE, state versions, and proof formats all meet at the same place.
Where this shows up in Polkadot
Merkle tries are not just an academic data structure inside the node. They show up directly in Polkadot's architecture:
- Relay chain and parachain blocks commit to state roots.
- Parachain validation uses proofs and witnesses so validators can check execution without trusting a collator's database.
- Light clients depend on finalized headers and storage proofs.
- Bridges need proofs that state existed on one consensus system before acting on another.
- Indexers use state roots and block hashes to make data extraction reproducible.
- Runtime migrations often have to account for trie format, proof size, and state access costs.
The trie is one of those pieces that is invisible when everything is working, but it shapes many of the constraints developers run into later.
Conclusion
Merkle tries give blockchains a verifiable database boundary. They let a block header commit to a large state without putting that state in the block, and they let clients verify small pieces of state without trusting the server that returned them.
In Polkadot SDK, the implementation is split across clean layers: FRAME defines typed storage, metadata lets clients build raw keys, sp_state_machine executes against trie-backed state, sp_trie and trie-db handle the Merkle Patricia trie mechanics, and the node database persists the encoded nodes and block data.
For application developers, the best abstraction is usually a typed query:
const account = await client.query.system.account(address)
For infrastructure developers, the real model is:
typed storage query
-> raw storage key
-> nibble path through trie
-> encoded value
-> proof nodes
-> state root in block header
Once that model clicks, a lot of blockchain storage behavior becomes easier to reason about: why historical queries need archive nodes, why proofs have size costs, why state version migrations matter, and why the state root is one of the most important fields in a block header.